Big Data systems are often composed of information extraction, preprocessing, processing, ingestion and integration, data analysis, interface and visualization components. Different big data systems will have different requirements and as such apply different architecture design configurations. Hence a proper architecture for the big data system is important to achieve the provided requirements. Yet, although many different concerns in big data systems are addressed the notion of architecture seems to be more implicit. In this paper we aim to discuss the software architectures for big data systems considering architectural concerns of the stakeholders aligned with the quality attributes. A systematic literature review method is followed implementing a multiple-phased study selection process screening the literature in significant journals and conference proceedings.
Various industries are facing challenges related to storing and analyzing large amounts of data. Big Data Systems become nowadays a very important driver for innovation and growth, by means of the insights and information that is obtained via the excessive processing of data. The business and application requirements vary depending on the application domain. Software architectures of big data systems have been previously studied sporadically/extensively. However, it is not easy to suggest a suitable software architecture for big data systems, when considering also both the application requirements and the stakeholder concerns [1].
The interactions and relations among the elements and all the elements as a whole that are necessary to reason about the system define the architecture of that system [2].. The architecture is constructed considering the driving quality attributes therefore it is important to capture those and analyze how these are satisfied by an architecture [3]. The requirements that are satisfied with the given architecture shall also match with the quality attributes.
In this study, we provide a systematic literature review (SLR) focused on the Software Architectures of the Big Data Systems in terms of the application domain, architectural viewpoints, architectural patterns, architectural concerns, quality attributes, design methods, technologies and stakeholders. The challenging part of the study was screening the publications from various domains. The variety of the application areas of big data systems brings along the dissimilar representations of the system architectures with flexible terminologies. In order to achieve the requirements provided by different stakeholders which derive different architectural configurations, a proper architectural design with consistent terminology is essential. We aim to focus on the software architectures for big data systems considering architecture design configurations derived by architectural concerns of the stakeholders aligned with the quality attributes which are implicit in design of various systems.
The application areas of the big data systems vary from aerospace to healthcare [4, 5], and depending on the application domain, the functional and non-functional concerns vary accordingly, influencing both the architectural choices and the implementation of big data systems. To shed light on the experiences reported in the recent literature with deploying big data systems in various domain applications, we conducted a systematic literature review. Our aim was to consolidate reported experience by documenting architectural choices and concerns, summarizing the lessons learned and provide insights to stakeholders and practitioners with respect to architectural choices for future deployment of big data systems.
The study aims to investigate the big data software architectures based on application domains assessing the evidence considering the interrelation among the data extraction area and the quality attributes with the systematic literature review methodology which is the suitable research method. Our research questions are derived to find out in which domains big data is applied, the motivation for adopting big data architectures and to identify the existing software architectures for big data systems We identified 622 papers with our search strategy. Forty-three of them are identified as relevant primary papers for our research. In order to identify various aspects related to the application domains, we extracted data for selected key dimensions of Big Data Software Architectures, such as current architectural methods to deal with the identified architectural constraints and quality attributes. We presented the findings of our systematic literature review to help researchers and practitioners aiming to understand the application domains involved in designing big data system software architectures and the patterns and tactics available to design and classify them.
The term “Big Data” usually refers to data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time. In general, Big Data can be explained according to three V’s: Volume (amount of data), Velocity (speed of data), and Variety (range of data types and sources). The realization of Big Data systems relies on disruptive technologies such as Cloud Computing, Internet of Things and Data Analytics. With more and more systems utilizing Big Data for various industries such as health, administration, agriculture, defense, and education, advances by means of innovation and growth have been made in the application areas. These systems represent major, long-term investments requiring considerable financial commitments and massive scale software and system deployments.
The big data systems are applicable to the data sets that are not tolerable by the ability of the generic software tools and systems [6]. The contemporary technologies within the area of cloud computing, internet of things and data analytics are required for the implementation of the big data systems. Such massive scale systems are implemented using long term investments within the industries such as health, administration, agriculture, defense and education [7].
Big data systems analytic capability strongly depends on the extreme coupling of the architecture of the distributed software, the data management and the deployment. Scaling requirements are the main drivers to select the right distributed software, data management and deployment architecture of the big data systems [8]. Big data solutions led to a complete revolution in terms of the used architecture, such as scale-out and shared-nothing solutions that use non-normalized databases and redundant storage [9].
As a sample domain, space business already benefits from the big data technology and can continue improving in terms of, for instance horizontal scalability (increasing the capacity by integrating software/hardware) to meet the mission needs instead of procuring high end storage server in advance. Besides multi-mission data storage services can be enabled instead of isolated mission-dedicated warehouse silos. Improved performance on data processing and analytics jobs can support activities such as early anomaly detection, anomaly investigation and parameter focusing. As a result, big data technology is transforming data-driven science and innovation with platforms enabling real time access to the data for integrated value.
The trend is to increase the role of information and value extracted from the data by means of improving the technologies for automatic data analysis, visualization and use facilitating machine learning and deep learning or utilizing the spatio-temporal analytics through novel paradigms such as datacubes.
The systematic literature review is a rigorous activity that is applied screening the identified studies and evaluating such studies based on the defined research questions, topic areas or phenomenon of interest. As a result of the evidence gathered for a particular topic, the gaps can be investigated further with supporting studies.
Evidence-based research is successfully conducted initially in the field of medicine and similar approaches are adopted in many other disciplines. Among the goals of the evidence-based software engineering, the quality improvement, assessing the application extent of the best practices for the software-intensive systems can be listed. Besides the evidence based guidelines can be provided to the practitioners as a result of such studies. Considering the benefits of the evidence based research, its application is valuable also in the software engineering field.
The systematic literature review shall be transparent and objective. Defining clear inclusion/exclusion criteria for the selected primary studies is critical for the accuracy and consistency of the output of the review. Well defined inclusion/exclusion criteria minimizes the bias and simplifies the integration of the new findings.
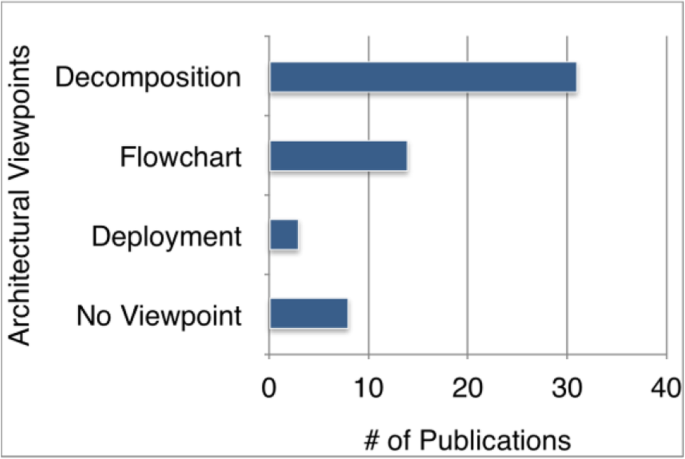
The software architecture is the high-level representation and definition of a software system providing the relationships between architectural elements and sub-elements with a required level of granularity [3, 10]. Views and beyond is one of the approaches to define and document the software architectures [11]. Viewpoints are generated to focus on relevant quality attributes based in the area of use for the stakeholder and more than one viewpoint can be adopted depending on the complexity of the defined system. In order to solve common problems within the architecture, architectural patterns are designed within the relevant context. Architectural patterns, templates and constraints are consolidated and described in viewpoints.
In this study, the SLR is applied for the software architectures of big data systems following the guidelines proposed in [12, 13] by Kitchenham and Charters. The review protocol that is followed is defined in the following sections.
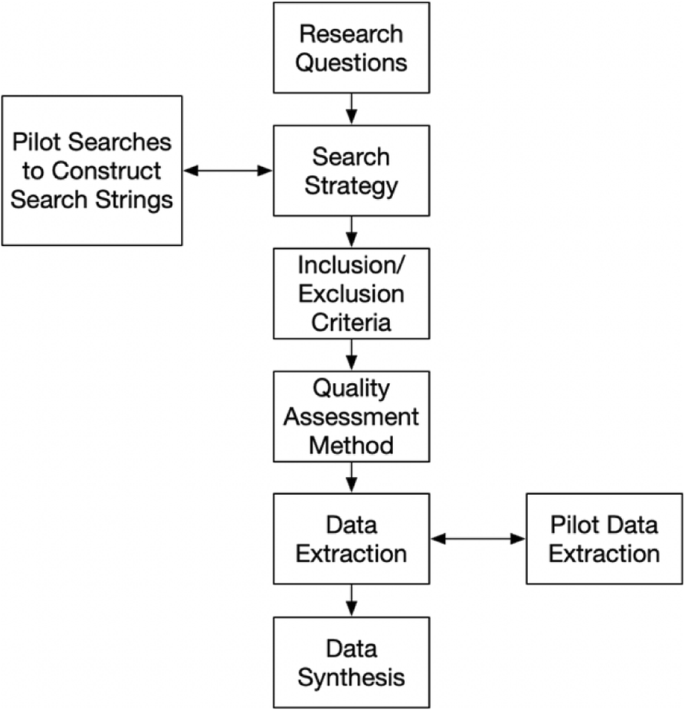
In order to apply the systematic literature review, a review protocol shall be defined with the methods to be used for reducing the overall bias. Figure 1 below shows the review protocol that is followed throughout this study:
The research questions are defined using the objectives of the systematic review as discussed in section 3.2 which is followed by drawing the scope (time range and publication resources) and the strategy (section 3.3). The search strategy is shaped by conducting pilot searches to form the actual search strings.
The appropriate definition of the search string reduces the bias and helps to achieve the target precision. The inclusion/exclusion criteria (section 3.4) is defined as the next step. The primary studies are filtered applying the inclusion/exclusion criteria. The success of the study selection process is assessed via the peer reviews of the authors.
The selected primary studies are passed through a quality assessment (section 3.5). Afterwards the data extraction strategy is built to gather the relevant information from the selected set of studies (section 3.6). The data extraction form is constructed and filled with the corresponding output to present the results of the data synthesis.
Constructing the research questions in the right way increases the relevancy of the findings and the accuracy of the SLR output. Validity and significance of the research questions is critical for the target audience of the SLR. Considering the fact that we are investigating the software architectures of the big data systems, the following research questions are defined to examine the evidence:
In this section, our search strategy is defined to find as many primary studies as possible regarding the research questions listed in section 3.2.
The search scope of our study consists of the publication period as January 2010 and December 2017 and search databases such as: IEEE Xplore, ACM Digital Library, Wiley Inter Science Journal Finder, ScienceDirect, Springer Link. Our targeted search items were both journal and conference papers.
Automatic and manual search are applied to search the databases.
In order to gather the right amount of relevant studies out of a high number of search process outputs, the selection criteria shall be aligned with the objectives of the SLR. A search strategy with high recall causes false positives and a precise search strategy will narrow down the outcome.
Initially a manual survey is conducted to analyze and bring out the search strings. Using this outcome, search queries are formed and run to obtain the right set of studies with optimum precision and recall rates.
The right method shall be applied to design the search strings with the relevant set of keywords which is critical for optimum retrieval of the studies. The keywords within the references section shall be eliminated and the keywords of the authors shall have higher weight. By means of the concrete set of keywords, the final search string is formed.
After the construction of the search strings, they are semantically adapted to the electronic data sources and extended via OR and AND operators. A sample search string is presented below:
(((“Abstract”: “Big Data” OR “Publication Title”: “Big Data”) AND (p_Abstract: “Software Architecture” OR “Abstract”: “System Architecture” OR “Abstract”: “Cloud Architecture” OR “Publication Title”: “Architecture”)))
Other search strings can be found in Appendix 1. Eliminating the duplicate publications, 662 papers are detected.
In order to omit the studies that are irrelevant, out of scope or false positive, aligned with the SLR guidelines, we apply the following exclusion criteria:
After the exclusion criteria is applied, the reduced amount of studies are presented in Table 1 where after applying EC1-EC5, which narrowed down our corpus to 341 papers. After applying criterion EC6, we concluded with 43 papers.
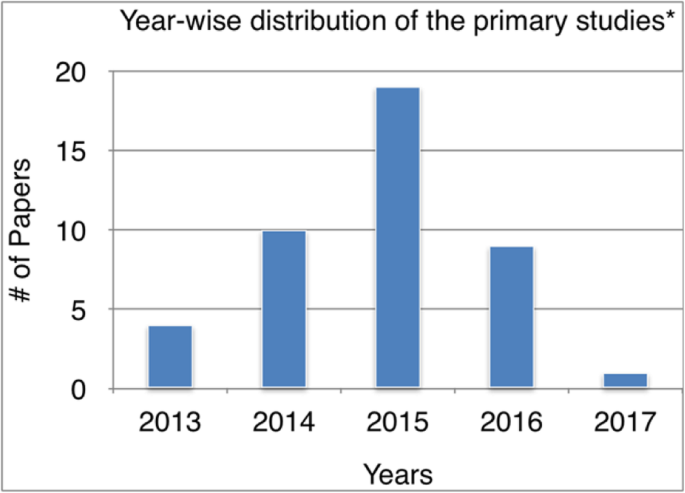
Table 4 presents the publication channel, publisher and the type of the selected primary studies as an overview. It can be derived from Table 4 that the selected primary studies mostly published by IEEE, Elsevier and ACM that are accepted as highly ranked publication sources. While “Conference on Quality of Software Architectures.” and “SIGMOD International Conference on Management of Data” are significant conferences, “Network and Computer Applications” and “VLDB Endowment” are remarkable journals for the software engineering domain. Besides, it can be indicated that the publication channels that have high impact in the domains other than software engineering are raising the number of papers with emphasis on big data system architectures within their publications. “Renewable and Sustainable Energy”, “Journal of Cleaner Production” and “Journal of selected topics in applied earth observations and remote sensing” can be listed among the remarkable publication changes from other domains.
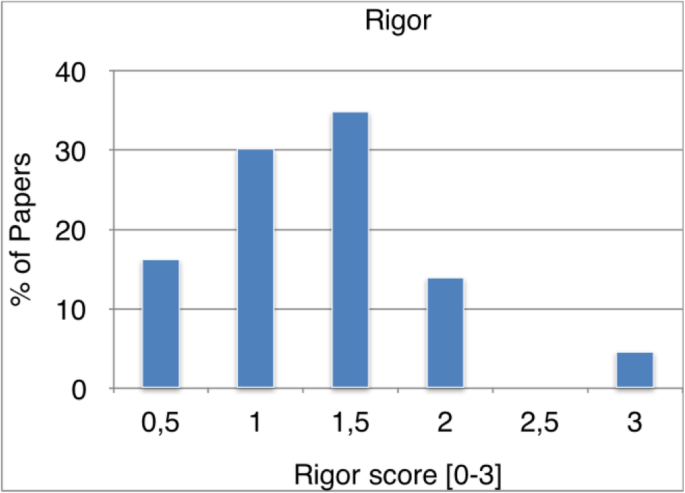
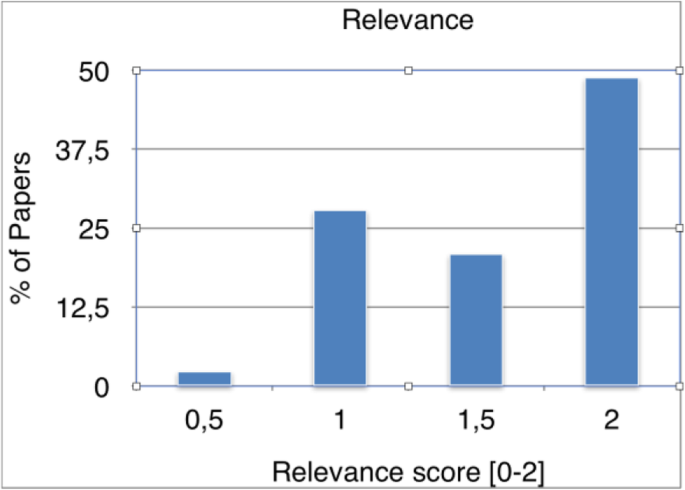
The trustworthiness of the primary studies were assessed in the context of rigor. The distribution of the quality scores of the primary studies from the dimension of rigor is presented in Fig. 4. We observe that the quality of rigor of the primary studies scored around the average values. While none of the papers scored below 0.5, the top scored papers are less than 10%. 30% of the studies scored 1 and similarly, the primary studies scored 1.5 are marginally above then 30%. The overall rigor quality appears as average.
The third quality dimension to report is relevance, which is illustrated in Fig. 5. As it can be inferred from Fig. 5, the primary studies are quite relevant to their research questions. About 50% of the studies scored the highest relevance score (i.e. 2), whereas the remaining studies mostly scored around 1–1.5 and only a few studies had a very low score. Therefore, we conclude that the selected primary studies are of high quality relevance.
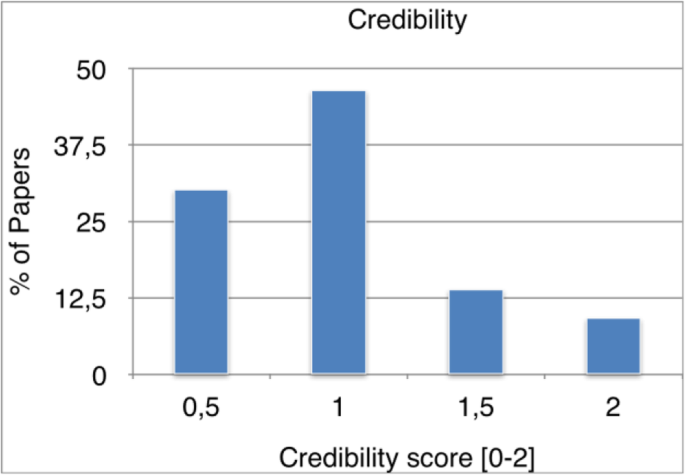
The credibility quality dimension is summarized in Fig. 6. The studies mostly have slightly below average credibility of evidence. Around 50% of the studies achieved score 1, which we considered fair, and around 30% scored 0.5 indicating a poor quality of credibility. We therefore conclude that the studies barely discuss major conclusions, and poorly list positive and negative findings.
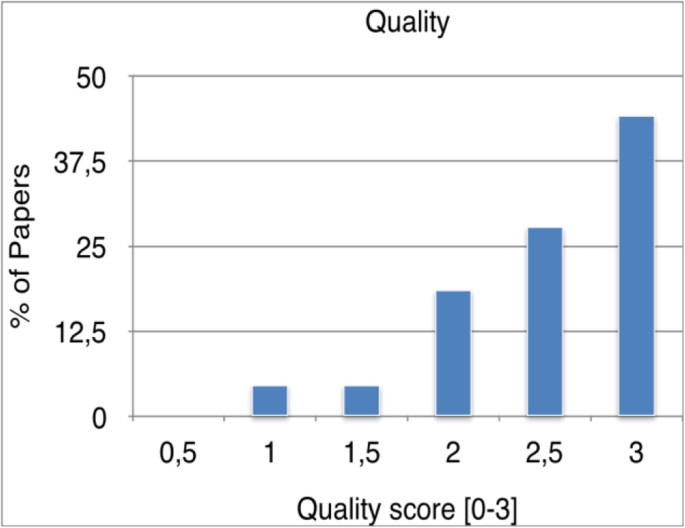
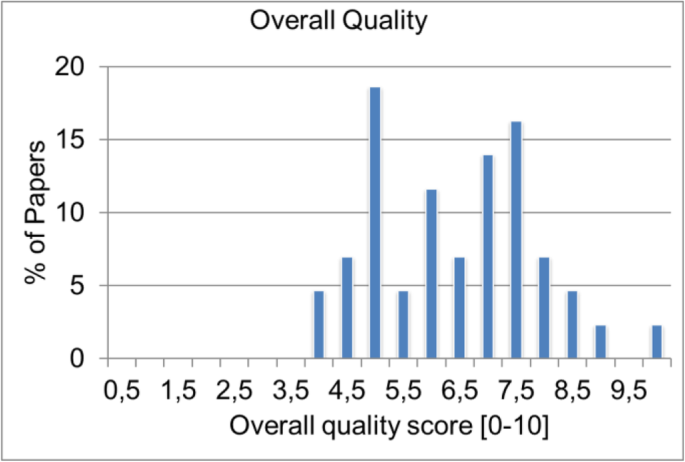
The overall quality scores are shown in Fig. 7, incorporating the quality scores for quality of reporting, relevance, rigour and credibility of evidence. Around 70% of the studies are above average quality (i.e. with a score greater than 4.5). 11% of the papers is in the category of poor quality ( < 5) and 29% of the papers have high quality scores (>7).
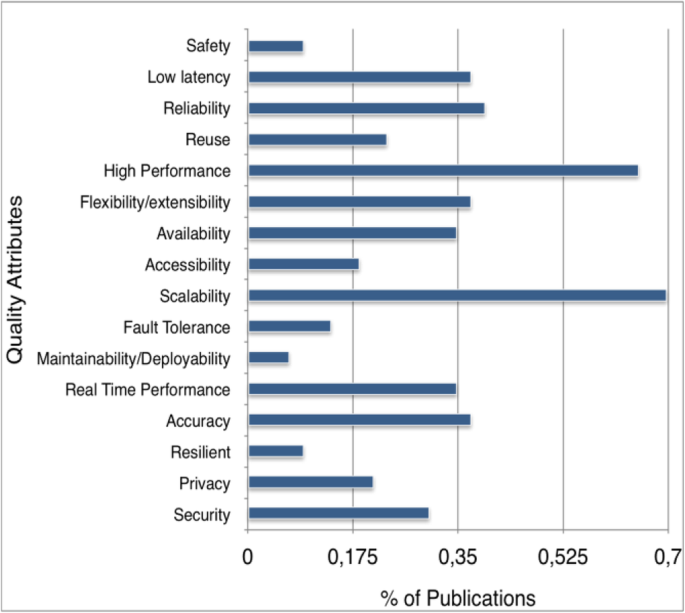
The distribution of the quality attributes per domain is presented in Fig. 8:
In this section, we present the results which are extracted from 43 selected primary studies in order to answer the research questions.
After screening the selected 43 primary studies, we extracted seven target domains and other domains that have less number of occurrence within the primary studies. The main domains can be listed as follows: Social Media, Smart Cities, Healthcare, Industrial Automation, Scientific Platforms, Aerospace and Aviation, and Financial Services (See Fig. 9).
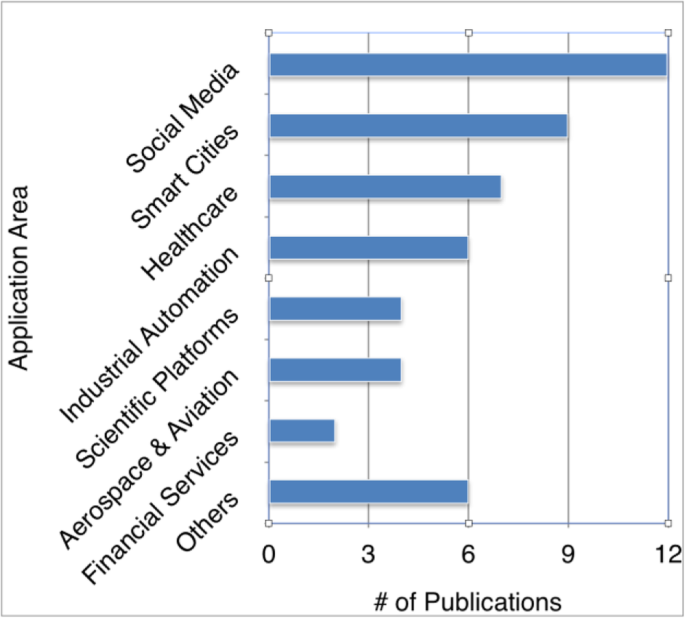
Table 6 shows the domain categories and their subcategories. For the smart cities domain, the subcategories are smart grid, surveillance system, traffic state assessment, smart city experiment testbed, network security and wind energy. Under the smart grid category, study 34 discusses a smart home cloud-based system for analyzing energy consumption and power quality, while study 42 describes a power system with a cloud-based infrastructure. Within the surveillance systems subcategory, study 24 presents a barrier coverage and intruder detection system, and study 18 introduces a system to track potential threats in the perimeters and border areas. Study 40 presents a cloud-based real-time traffic state assessment system. For the smart city experiment testbed, studies 5, 9, 22 discuss system infrastructures that analyze real-time and historical data from the perspectives of parking occupation, heating and traffic regulation. Study 35 is listed under the network security subcategory for smart pipeline monitoring system. Under the sub-category of wind energy, study 18 discusses a system which uses climate data to predict the most optimal usage of wind energy.
There are five architectural patterns reported within the selected primary studies which are listed as follows: Layered (data is forwarded from one level of processing to another in a defined order), cloud based (architectural elements are in cloud), hybrid (combination of different architectural patterns) and multi-agent (a container/component architecture, containers are the environment and components are the agents) (Fig. 11).
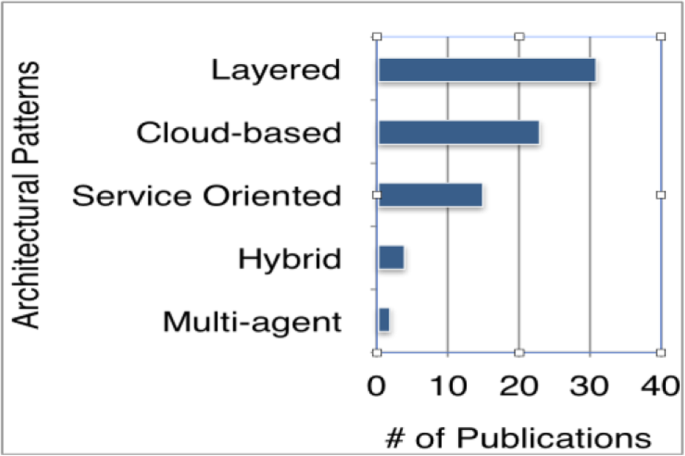
In [18], the system architecture proposed for cleaner manufacturing and maintenance is composed of 4 layers that are data layer (storing big data), method layer (data mining and other methods), result layer (results and knowledge sets) and application layer (uses the results from result layer to achieve the business requirements). In [19], the traditional 3 layered architecture of the financial systems was adopted: front office (interaction with external entities, data acquisition and data integrity check), middle office (data processing), back office (aggregation and validation). While at least a 3-layered approach is applied for most of the application domains and two layers with processing and application layer driving the results via aggregation and validation is consistent for all domains, the layers on top are adopted depending on the application domain.
For web-based systems, lambda architecture is implemented in [4] with the batch (non-relational) and streaming layer (real-time data) completely isolated, scalable and fault tolerant. For machine to machine communication, a 4 layer architecture is presented with the service (business rules, tasks, reports), processing (Hadoop, HDFS, MapR), communication (m2m, binary/text I/O) and data collection layers. The layered architecture of the AsterixDB (an open source big data management system) is shown in [2]. Hyracs layer and Algebrics Algebra layer are layers that are represented within the software stack. Hyraces layer accepts and manages the parallel data computations (processing jobs and output partitions). Algebrics layer which is data model neutral and supports high level data languages, aims to process queries. Banian system architecture which is described in [20] consists of 3 layers which are storage, scheduling and execution and application layer and the system provides better scalability and concurrency. The architecture proposed in [15] is for intruder detection in wireless sensor networks. Three layered big data analytics architecture is designed: wireless sensor layer (wireless sensors are deployed), big data layer (responsible for streaming, data processing, analysis and identifying the intruders) and cloud layer (storing and visualizing the analyzed data).
Cloud based architectures are also frequently observed among the selected primary studies. In [2], a scalable and productive workflow based cloud platform for big data analytics is discussed. The architecture is based on the open source cloud platform ClowdFlows. Model view controller (MVC) architectural pattern is applied. The main components are data storage, data analytics and prediction and data visualization which are accessible via a web interface. The architecture of [17] uses the cloud environment (Amazon EC2 cloud service) to store the data collected from the sensors and host the middleware. Overall system is composed of sensors, sensor boards, bridge and middleware. Another cloud architecture is used to construct a cloud city traffic state assessment system in [21] with cloud technologies, Hadoop and Spark. Clustering methods such as K-Means, Fuzzy C-Means and DBSCAN are applied to detect the traffic jam. The architecture has 2 high level components which are data storage and data analysis and computation. While data storage is based on Hadoop HDFS and NoSQL, data analysis and computation part utilizes Spark for high speed real time computation. For all of the big data systems applying cloud based architectures, the cloud is used to resolve the scalability problem of the data collection.
In order to provide the users interactive real time processing of the satellite images, a cloud computing platform is introduced for the China Centre for Resources Satellite Data and Application (CCRSDA) in [12]. The platform aims low latency, disk-space customization and remote sensing image processing native support. The architecture consists of application software including image search, image browsing, fusion and filter, web portal containing private file center, data center, app center, route service and work service, virtual user space management, Moosefs, ICE and Zookeeper and virtual machine management (3 service levels, Saas, PaaS and IaaS respectively).
One of the primary studies [22] discusses a multi-agent architecture for real time processing. The lambda architecture is modelled as a heterogeneous multi-agent system in this study as 3 layers (batch, serving and speed layer). The communication among the components within the layers is achieved via agents with message passing. The multi agent approach simplifies the integration.
Service oriented architectures are frequently applied for big data systems. In [23] a cloud service architecture is presented. It has three major layers which are an extension of semantic-wiki, rest api and SolrCloud cluster. The architecture explores a search cluster for indexing and querying. Another system architecture described in [5] is based on a variety of rest-based services for the flexible orchestration of the system capabilities. The architecture includes domain modelling and visualization, orchestration and administration services, indexing and data storage.
Cybersecurity
Software systems are developed and integrated aligning with a software application architecture and deployed when the system is mature enough satisfying the acceptance criteria for the system release and deployment. If the maturity of the system is measurable, the quality metrics are utilized to assess the performance of the system. While a system is performing, the vulnerabilities rooted in the system architecture, deployment configuration or the network architecture enables an external or internal entity to perform malicious activities. Tracing or pre-detecting the vulnerabilities residing within the system could support the decision process for maintenance, risk analysis, implementation or system extension processes. Not only for the system performance but also for the vulnerability analysis which could directly have an impact on the performance itself, system specific metrics could be selected and defined. However, due to the rapid technological developments, system specific and implementation specific codes, artefacts and configurations and maintenance activities, resulting with the right set of metrics is a challenge.
According to [24] “Resilience – i.e., the ability of a system to withstand adverse events while maintaining an acceptable functionality – is therefore a key property for cyberphysical systems”. Primary approaches to measure the resilience could be model based or metric based. As a metric based approach, resilience indexes are defined to be extracted from system data such as logs and process data as a quantitative general-purpose methodology [24].
Resilience readiness level metrics are proposed in [25], as shown in Table 9 and as a matter of fact, the aspects that the big data systems are related to the readiness levels from the cybersecurity point of view are outlined and discussed.
Table 9 Resilience readiness and big data cyber security aspectsAnother study in the survey format is composed in 2018 which is called “Big Data Meets Cyberphysical Systems” [28], that summarizes the impact of the increasing variety of the cyberphysical systems and the amount of sensor data produced. The study also discusses the cyber attacks targeting such systems. Centroid based clustering and hierarchical clustering are listed as two groups of clustering methods. K-means is an example of the clustering methods and it has the empty clustering problem. For the hierarchical clustering, the clusters are defined based on similarity measures such as distance matrices and the clustering speed and accuracy is higher comparing to the other algorithms like k-means.
Integration is a concern in cyberphysical systems in critical infrastructures due to the computational challenges observed while applying techniques for data confidentiality and privacy protection [34]. Semi or fully autonomous security management could be adapted according to the needs of the application to be implemented. The solutions could have high cost by means of latency, power consumption or management complexity.
Deep learning
Application of deep learning in big data is discussed in [15], stating the challenges as:
In [19] emotion recognition is achieved via the fusion of the outputs of convolutional neural networks (CNN) and extreme learning machines (ELM) and for final classification SVM is used. The architectural approach could be characterized as hybrid application architecture having CNN and SVM with ELM fusion. Achieving high accuracy with this approach, it is observed that data augmentation improved the accuracy further.
Sentiment analysis
In [29] is analysed based on topics of sensitive information. In order to accomplish the analysis, bidirectional recurrent neural network (BiRNN) and LSTM are combined to form BiLSTM to ensure having context information continuously. The architecture has a layered structure.
The brand authenticity analysis is carried out in [30]. The quality commitments for the tweets are instantly sharing sentiments, sharing complaints, processing complaints and the quality of ingredients. Statistica 13 software is used fort SVM analysis.
In order to state the plausibility of the results, within this research question we will be discussing to which extent the audience of this study can rely upon the outcomes. Among the various definitions to address the strength of evidence, for this SLR we selected the Grading of Recommendation Assessment, Development and Evaluation (GRADE). As it can be observed from the Table 10 (adopted from [17]), there four grades which are high, moderate, low and very low to assess the strength of evidence which takes into consideration the quality, consistency, design and directness of the study. Comparing to the observational studies, experimental studies are graded higher by the GRADE system. Among the primary studies in this review, 16 (37%) are experimental. The average quality score of these studies is 6,4 which means that our studies have a moderate strength of evidence based on the design (Table 11).
Table 10 Definitions used for grading the strength of evidence Table 11 Average quality scores of experimental studiesMost of the primary studies we analyzed do not include explicitly a quality assessment by means of our quality criteria which are rigor, credibility and relevance. Therefore there is a risk of bias implied by the low quality scores.
In terms of quality, from the rigor perspective, we can observe a variety of presentation structure and reporting methods which complicates the comparison of the content. For most of them the aim, scope and context are clearly defined, however for some of them the results are not clearly validated by an empirical study or the outcomes are not quantitatively presented. Besides, throughout many studies, research process is documented explicitly but some of the research questions remained unanswered. Considering credibility, while the studies tend to discuss credibility, validity and reliability, they generally avoid discussing negative findings. The conclusions are quite relating to the purpose of the study, and the results are relevant while not always practical.
Considering the fact that the presentation of the research questions and the results extremely varying from study to study, it is very complicated to analyze the consistency of the outputs of the primary studies. As a result, sensitivity analysis and synthesis of the quantitative results were not feasible.
With respect to directness, the total evidence is moderate. According to Atkins et al., (2004) a directness is the extent to which the people, interventions, and outcome measures are similar to those of interests. The people were experts from academy or industry which are within the area of interest. The outcomes are not restricted for this literature survey. A considerable amount of primary studies answers the research questions and validates the outcome quantitatively.
Assessing all elements of the strength of evidence, the overall grade of the impact of the big data system architectures presented throughout the primary studies is moderate.
Various dimensions of improvements are analyzed, implemented and experimented throughout the studies listed in previous chapters. In AsterixDB, the performance of the functions within dataflows are planned to be improved via introducing further parallelism for function evaluation in pipeline.
The performance is measured in the presented big data architectures for construction waste analytics by means of accuracy. Application areas within the internet of thigs field the challenge is scaling the platform, privacy and security both for the data and the system. Assessing the maturity of a big data system and which metrics to measure the maturity is another area to be explored.
Hybrid architectures are not often observed among the primary studies, however could be benefited more as in the application architecture having CNN and SVN for the sentiment analysis. Integration concerns for big data systems within the cyberphysical domain is to be further investigated (Tables 12, 13, 14 and 15).
Table 12 Benefits and limitations of the primary studies a Table 13 Difference and importance of the primary studies aTable 14 Benefits and limitations of the Other State of Art Studies a focusing on the application domain